Usage
To use a data source, it must be attached to one (or more) stub(s) of a mock API. Data sources have two primary functions when attached to a stub mapping:- Custom stub matching based on the result of a configurable query
- Providing data to be used in a stub’s response template.
Attaching a data source to a stub
Once your data source has been set up correctly, following the steps in creating a CSV data source, or creating a database data source it can be attached to a stub. To attach a data source to a stub in WireMock Cloud, navigate to the desired stub and open the “Data source” section.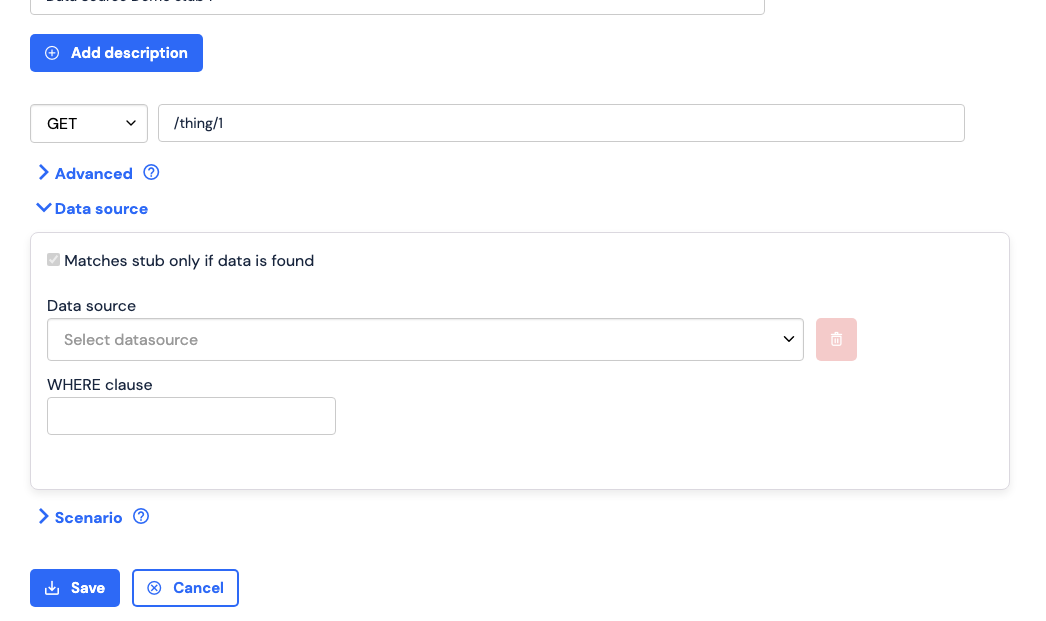
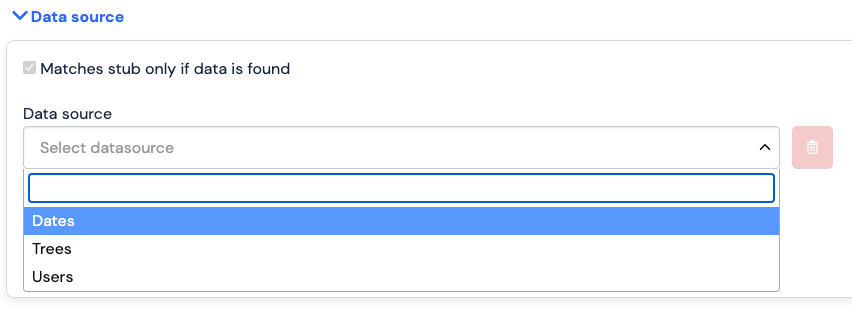
WHERE clause, or leave blank. The WHERE clause allows you to use ORDER BY, LIMIT and OFFSET to get
consistent ordering and pagination.
Deleting a data source from a stub
If you no longer wish for your stub to have the capabilities provided by data sources, you can detach/delete the data source from the stub at any time. To detach a data source from a stub, simply open the “Data source” section of the desired stub and click the delete button, then save.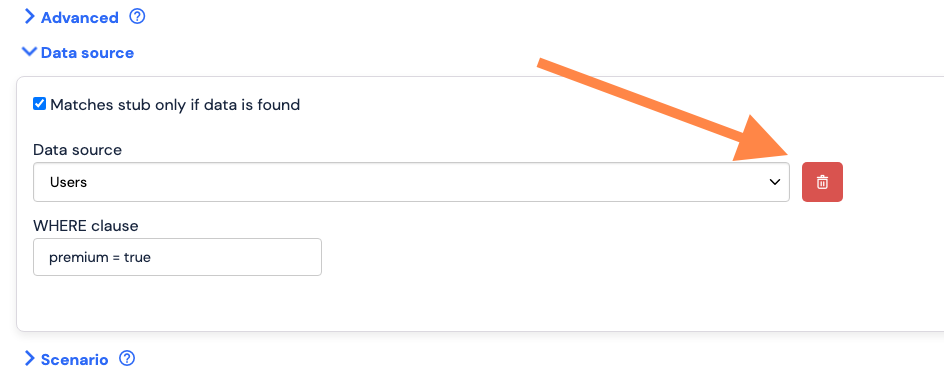
Which stubs can reference attached data sources?
Once a data source has been created, it can be used by all stubs within the organization. However, a stub can only have a single data source attached to it at a timeCustom stub matching
Attaching a data source to a stub allows the stub to only match a request when the data source returns non-empty data. The data that a data source returns for a given request and stub can be filtered via a configurable ANSI standard SQL query. This query is attached to a stub alongside the data source.WHERE clause of a standard SQL statement that is executed on the data source.
The columns of a data source can be queried as if they were columns of an SQL table.
For instance, if your data source has an “age” column of type INTEGER, you can retrieve all rows where age is greater than twenty-five using the query age > 25.
Each data source column type maps to an SQL column type:
All standard SQL operators of each type are supported in the attached query (e.g.
+, -, =, <, >, AND, OR, EXISTS, BETWEEN, etc.).
Handlebars templating in query
The data source query supports handlebars templating in order to dynamically create queries based off the contents of an incoming request. The model available in the template is the same request data model that is provided in the response template. For example, if your data source contains a “first_name” column, you can filter the data source via a query parameter provided in the request like so:first_name = '{{request.query.name}}'.
When a request is sent to the mock API with a name query parameter, the value of this parameter will be inserted into the WHERE clause.
So a query string that contains name=alice will result in a WHERE clause of first_name = 'alice'.
Potential pitfalls
As in standard SQL, to reference a column whose name contains whitespace or starts with a digit, the column name must be surrounded by double quotes (e.g."first name" == 'bob').
Quoting a column name also enforces case sensitivity (i.e. the casing in the query must match the casing of the column name exactly).
Currently, only simple WHERE clause expressions that are part of the ANSI standard SQL specification are supported including
ORDER BY, LIMIT and OFFSET. Sub-queries are not officially supported.
An empty query will return the entirety of the data source.
Thus, the stub’s data matcher will always return a match, as long as the data source itself is not empty.
Disabling matching
This matching functionality can be disabled via a checkbox.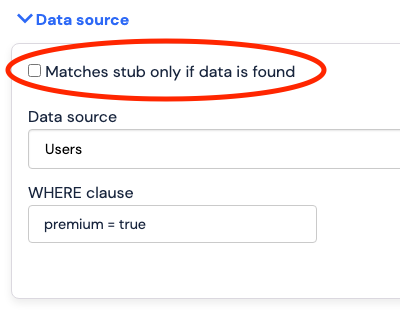
Rendering data in response
Attaching a data source to a stub allows the data contained in the data source to be rendered in the response via response templating. The data available from the data source for a particular request’s response is the result of evaluating the stub’s data source query for that request. For instance, if a stub is configured with a query ofage > 25, then the data available in the response template will be limited to all rows whose “age” column exceeds twenty-five.
This data can be referenced in the response template via the data.items property.
This property is a list of all the rows returned by the data source query.
For example, to render a JSON array of the name of each returned row, the following response template could be used:
{{ data.items.0.name }}').
Potential pitfalls
Field names containing whitespace or starting with a digit must be surrounded by square brackets. For example, a column with the name “first name” would be referenced like so:{{ data.items.0.[first name] }}'.
Supplying an empty query will provide the entirety of the data source to the template model.